Данный кейс о том, как мы разгрузили менеджеров клиента от рутины и ускорили их реакцию на запросы в 2,5 раза, благодаря внедрению локально развернутого ИИ-ассистента.

Уровень профессионализма менеджеров и скорость ответа на вопрос для B2B-бизнеса — ключевой элемент удержания клиента и показатель качества продукта. Для небольших компаний, работающих со сложным, кастомизированным оборудованием, каждый запрос уникален, но при этом сотни раз повторяется в своей основе.
Во многих компаниях сотрудники вынуждены тратить до 70% своего рабочего времени не на решение проблемы клиента, а на трудоемкий поиск нужной технической документации, истории обращений и специфических настроек в лабиринтах внутренних баз данных.
Содержание
- Знакомство с клиентом и его запросом
- Поставленная задача
- Реализация внедрения AI-ассистента
- Сложности проекта, тестирование и процесс отладки
- Результаты и метрики
- Что нужно, чтобы внедрить корпоративного ИИ-ассистента?
Исходная ситуация: «разрозненные» запросы и фрагментированные данные
Клиент — компания из 70 сотрудников, специализирующаяся на разработке и внедрении систем промышленного мониторинга и высокоточных IoT-сенсоров для нефтегазовой отрасли и промышленных предприятий. Каждый внедряемый проект уникален: оборудование требует тонкой настройки, а обслуживание — индивидуального подхода.
Через внутреннюю CRM компании поступает множество обращений:
- Запросы на техобслуживание и диагностику;
- Вопросы по поставке нового оборудования или комплектующих;
- Технические консультации, связанные с конкретной конфигурацией сенсоров на объектах;
- Уточнения по введению устройств в эксплуатацию и пр.
Большинство запросов содержали комбинацию стандартных вопросов и уникальных деталей. Например: «Какая конфигурация рекомендована для сенсора №421 на объекте ХХХ согласно параметрам, заданным в акте настройки от 12.03.2025?»
Менеджеры первой линии (5 человек) тратили в среднем 15–20 минут на один запрос. Большую часть времени отнимал трудоемкий поиск в огромной базе данных.
Основная проблематика:
- 65-70% времени менеджера уходило на поиск (иногда безуспешный) нужных файлов в разных внутренних хранилищах, изучение цепочек коммуникации, актов обслуживания, паспортов устройств и истории поставок. Если поиск не приносил результатов, менеджеры обращались за информацией к колегам и ждали, когда те освободятся и предоставят информацию.
- Вопросы часто повторялись, но речь шла о разных клиентах и конфигурациях, поэтому всё равно требовалось искать документацию по конкретному клиенту.
- Низкая скорость реакции сказывалась на удовлетворённости крупных промышленных заказчиков.
Задача: ускорить обработку запросов и автоматизировать поиск данных
Ключевая цель клиента — значительно повысить скорость обработки запросов, не нарушая требований безопасности и конфиденциальности.
Целевые метрики:
- Сократить среднее время обработки запроса.
- Максимально сократить время, уходящее у менеджера на поиск нужной информации.
Наиболее эффективным решением поставленной задачи является оптимизация поиска по базе данных и подключение к процессу AI-ассистента, который будет помогать менеджерам быстрее отвечать клиентам.
Поэтому СТЕК предложил решение — интеграцию интеллектуального ассистента созданного на основе LLM прямо во внутреннюю CRM-платформу. ИИ автоматически собирает релевантные данные, формирует ответ и помогает менеджерам значительно ускорить процесс взаимодействия с клиентами.
LLM (Large Language Model) — это большая языковая модель, тип искусственного интеллекта, который обучен понимать и генерировать текст, отвечать на вопросы, анализировать информацию и выполнять различные интеллектуальные задачи.
Реализация: интеграция локального ИИ-ассистента в CRM
Один из основных вызовов проекта — требование абсолютной конфиденциальности информации о клиентах, объектах и технических параметрах. Все данные должны находиться в закрытом контуре компании. Поэтому ИИ-модель была развернута полностью локально, внутри инфраструктуры клиента.
Мы использовали open sourse модель LLM, которая соответствует поставленным задачам и имеет необходимые опции, поэтому клиенту не пришлось тратить значительные средства и время на её обучение.
Для взаимодействия с CRM клиента было использовано API, а также написан специальный бот, который собирает исходную информацию, обрабатывает её и предоставляет менеджерам в удобном виде.
Архитектура решения включает четыре этапа:
1. Регистрация запроса в CRM
Обращение поступает в CRM из любого канала — сайта, почты, личного кабинета, телефона — и автоматически классифицируется: сервисный запрос, поставка оборудования, консультационный вопрос и т.д.
2. Автоматический гибридный поиск
Разработанный алгоритм запускает расширенный поиск по всей корпоративной информации:
- История обслуживания данного клиента;
- Параметры конкретного оборудования;
- Данные по последним поставкам;
- Результаты диагностики, акты ввода в эксплуатацию;
- 3–4 релевантные статьи или инструкции из базы знаний.
Особенность гибридного поиска в том, что алгоритм не возвращает тысячи документов, а формирует узкую подборку из 5–10 максимально релевантных материалов.
3. Обработка локальным ИИ-ассистентом
ИИ получает только отфильтрованный пакет данных и структурированный промт.
Он формирует:
- Точный технический ответ;
- Рекомендации;
- Ссылки на исходные документы;
- Корректное оформление в корпоративном стиле.
Ассистент не пишет «шаблонные ответы» — он формирует персонализированный технический документ, который менеджер проверяет, корректирует при необходимости и отправляет клиенту.
4. Вывод и валидация

В CRM-интерфейсе менеджер получает:
- Готовый структурированный ответ;
- Краткую сводку данных, использованных ИИ;
- Ссылки на документы;
- Возможность внести корректировки.
Благодаря мощному фильтру на первом этапе ИИ не тратит время и ресурсы на обработку гигантских объемов данных. Он работает только с максимально релевантной, подготовленной информацией, что обеспечивает высокую скорость, точность и низкие операционные расходы.
Система была развернута на мощностях клиента, расположенных в закрытом контуре компании. Для работы сервиса с внутренней базой данных размером 500 Гб, мощности сервера составили:
- Сервер с данными: 8 CPU, 32 GB RAM, 450 GB SSD;
- VM для ИИ: 12 CPU, 32 GB RAM, 70 GB SSD, 24 GB VRAM;
- VM для автоматизации: 6 CPU, 8 GB RAM, 90 GB SSD;
Сложности проекта, тестирование и отладка сервиса
На данный момент AI-технологии несовершенны, поэтому недостаточно просто установить нейросеть на сервер и наслаждаться её работой. Требуется тщательный процесс отладки. В данном случае, так как мы использовали оптимизированную систему — поиск+LLM — одной из важных задач было максимально проработать алгоритм поиска.
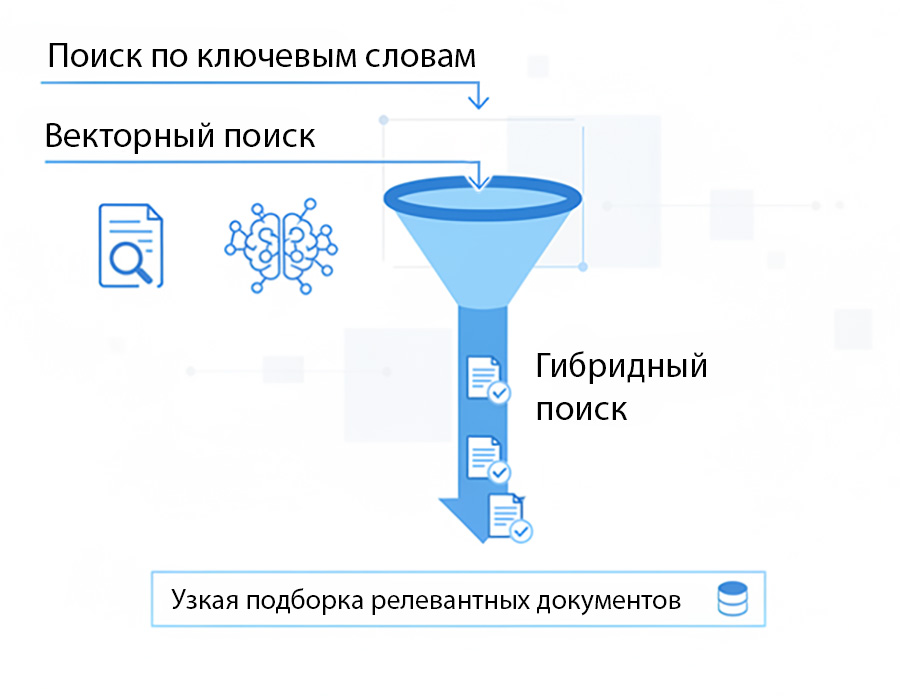
Изначально, до момента отладки, поиск по базе данных выдавал неполную или же, наоборот лишнюю информацию, несоответствующую запросу. Эта проблема была решена внедрением дополнительных этапов поиска и фильтрации данных.
Мы настроили гибридный поиск — это метод, который объединяет два типа поиска: классический полнотекстовый (по ключевым словам) и более современный векторный (семантический), чтобы получить более точные и релевантные результаты.
Как это работает
- Поиск по ключевым словам ищет документы, содержащие конкретные слова из вашего запроса, как это делали старые поисковые системы.
- Векторный поиск анализирует семантическую связь между запросом и содержанием документов, даже если они не содержат точных ключевых слов, но имеют схожий смысл.
- Объединение результатов. Полученные результаты от обоих типов поиска затем объединяются с помощью алгоритмов ранжирования.
Благодаря этому AI-ассистент получает корректную и структурированную информацию, что позволяет избежать «галлюцинаций» в работе ИИ.
Результаты и метрики
После внедрения и трёхмесячного пилотного периода компания получила следующие результаты:
| Метрика | Исходный показатель | Итоговый показатель | Результат |
|---|---|---|---|
| Среднее время обработки запроса | 12–15 минут | 4.5–5.5 минут | Сокращение примерно на 70% |
| Уровень загрузки менеджеров поиском нужной информации | Около 70% рабочего времени | <10% | Менеджеры стали редакторами ответов |
| Коэффициент повторных обращений с тем же вопросом | 18% | 14% | Снижение на 4 процентных пункта или на 22% относительно количества обращений (благодаря полноте ответа) |
Ключевой эффект: менеджеры были разгружены от рутины поиска. Теперь они больше сконцентрированы на выстраивании коммуникации и решении сложных, нестандартных ситуаций, тогда как типовые повторяющиеся запросы обрабатываются за считанные минуты.
Итог
Проект показывает, что современный ИИ не обязательно должен быть масштабным облачным сервисом. При правильной архитектуре локальное решение может дать мощный эффект и полностью изменить работу клиентского сервиса.
Наш подход «Сбор информации → Фильтрация → Локальный ИИ → Человек-контролёр» стал универсальным шаблоном, который можно внедрить в любую компанию, работающую с большим количеством структурированных запросов.
ИТ-интегратор СТЕК помогает превращать корпоративные базы знаний в инструмент ускорения процессов, повышения лояльности клиентов и улучшения качества обслуживания. Если вы стремитесь к ускорению бизнес-процессов — обращайтесь к нам за услугой внедрения ИИ в промышленное предприятие.
