
Кибератаки все чаще нацелены на парализацию бизнеса. Представьте ситуацию: сотрудники приходят в офис, а у них не работает электронная почта, нет доступа к сетевым дискам и базам данных, отсутствует интернет-соединение. Даже корпоративный Wi-Fi не функционирует.
В этом кейсе мы расскажем, как наша команда в экстренном режиме помогла не только вернуть систему к жизни, но и построить новую, более безопасную и отказоустойчивую среду с нуля.
Содержание:
- Исходная ситуация: полная остановка бизнес-процессов
- Основная задача: аварийное восстановление данных после комплексного киберинцидента
- Реализация: как мы восстановили инфраструктуру за несколько дней
- Особенности и сложности проекта
- Результаты: работоспособность восстановлена, безопасность обеспечена
Кому будет интересен этот кейс:
- Руководителям компаний с распределённой сетью офисов (несколько офисов, филиалов), где критически важна согласованная работа всех IT-компонентов.;
- IT-директорам и администраторам, ответственным за безопасность инфраструктуры;
- Собственникам бизнеса, пережившего инцидент информационной безопасности и желающим не просто «залатать дыры», а кардинально усилить свою защиту.
Исходная ситуация: полная остановка бизнес-процессов
Клиент — крупная компания с головным офисом в Санкт-Петербурге и несколькими региональными филиалами. Парк техники насчитывает несколько сотен компьютеров. Ранее организация сотрудничала с нами, но позже перенесла мощности к другому облачному провайдеру и развивала IT-отдел собственными силами.
Недавно компания столкнулась с критическим инцидентом, в результате которого IT-инфраструктура была полностью скомпрометирована:
- Доступ к серверам и рабочим станциям был потерян;
- Бухгалтерия, продажи и логистика остановились;
- Дисковые системы на компьютерах оказались зашифрованы;
- Сетевое оборудование требовало полной перенастройки.
Злоумышленники не просто шифровали данные, а полностью удалили всю виртуальную инфраструктуру в облаке, сменили пароли на всём сетевом оборудовании в офисе и заразили часть компьютеров.
Сотрудники не могли работать, IT-отдел потерял контроль над инфраструктурой, а бизнес-процессы остановились. Требовалось экстренное реагирование.
Это не первый случай в нашей практике. Мы уже неоднократно выполняли срочное восстановление сети после кибератаки, обновление IT-инфраструктуры компании после кибератаки, восстановление ИТ-инфраструктуры после шифровальщика, а также экстренное восстановление базы данных после взлома сервера 1С.
Основная задача: аварийное восстановление данных после комплексного киберинцидента
Клиенту требовалась не просто техническая помощь, а комплексное сопровождение. Основные задачи были сформулированы по ходу работы:
- Оценить зону поражения — понять, что можно восстановить, а что утеряно безвозвратно;
- Восстановить базовую работоспособность офиса — интернет, локальную сеть, доступ к рабочим станциям;
- Построить новую защищённую инфраструктуру — в облаке и на месте;
- Обезопасить рабочие станции и не допустить повторного заражения;
- Организовать надёжное резервное копирование и мониторинг на будущее.
Всё это нужно было сделать параллельно, в условиях полного хаоса и отсутствия доступа даже к конфигурациям сетевого оборудования.
Реализация: как мы восстановили инфраструктуру за несколько дней
Учитывая критичность ситуации, мы действовали без длительных согласований ТЗ.
В проект мгновенно включилась группа быстрого реагирования из 4 человек: три системных инженера экспертного уровня и специалист по информационной безопасности.
Наш подход к аварийному восстановлению данных (DR) всегда включает четкое планирование.
Работы велись параллельно по трем направлениям, для понимания свели в наглядную схему:
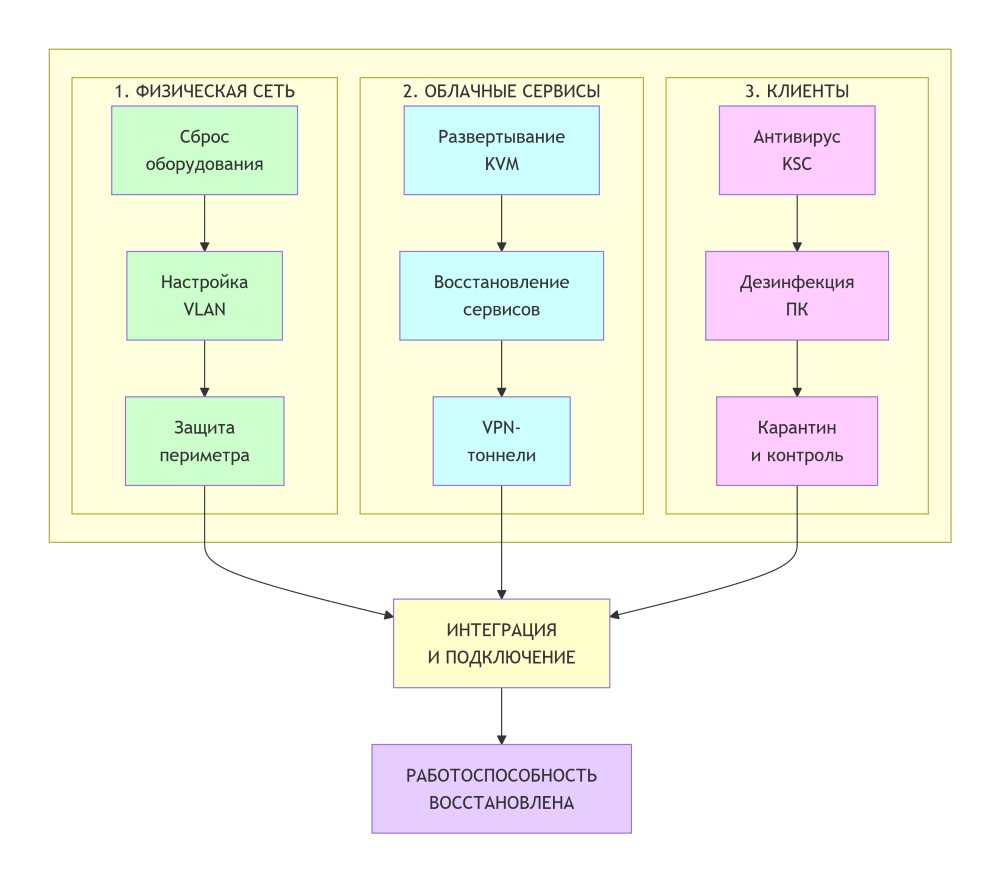
1. Перехват управления сетью (Physical Layer)
Первым делом инженеры прибыли в офис клиента для оценки зоны поражения. Поскольку хакеры сменили пароли на всем сетевом оборудовании (более 15 устройств MikroTik и коммутаторов), а бэкапы конфигураций были недоступны, восстановление шло в ручном режиме.
Мы физически сбрасывали каждое устройство до заводских настроек и конфигурировали сеть с нуля:
- Спроектировали новую архитектуру локальной сети с использованием VLAN;
- Настроили маршрутизацию между этажами и отделами;
- Развернули безопасный Wi-Fi с жестким разделением на гостевые и рабочие зоны;
- Защитили периметр, внедрив строгие правила фильтрации трафика на главном шлюзе.
Это был первый, критически важный шаг к возвращению связи.
2. Построение облака и восстановление сервисов

Параллельно другой частью команды велась удаленная работа. Наши инженеры начали аварийное восстановление данных в новой, безопасной среде.
Мы инициировали полное пересоздание ИТ-ландшафта. Буквально за сутки был подготовлен фундамент: контроллер домена для учетных записей, заготовки под серверы 1С и базы данных, площадка для развертывания корпоративного портала.
Ядром новой системы стало частное облако на базе KVM. Наши действия разделились на три параллельных потока:
- Между только что настроенным офисом и новым «цифровым островом» оперативно проложили защищенные VPN-тоннели, создав безопасный «мост» для будущей работы;
- Подготовили «чистые» виртуальные машины для критичных сервисов;
- Совместно с IT-отделом заказчика начали восстановление ролей: Active Directory, файловых серверов, SQL, терминальных серверов 1С и Битрикс24.
Примечание: IT-отделу заказчика удалось найти способ извлечь часть данных, которые не были удалены безвозвратно. Наша задача заключалась в предоставлении надежной и безопасной платформы для их развертывания.
3. «Карантин» и зачистка рабочих станций
Самый рискованный этап — подключение сотен компьютеров сотрудников к новой «чистой» сети. Если хотя бы один ПК остался зараженным, атака могла повториться.
- Экстренно развернули новый сервер управления антивирусной защитой (Kaspersky Security Center);
- Провели массовую дезинфекцию парка машин;
- Для сложных случаев разработали инструкции для штатных админов по ручной проверке каждого ПК.
Только после полной проверки («зеленого света») сотрудники получали доступ к восстановленным сервисам. После стабилизации головного офиса мы по аналогичной схеме восстановили работу двух региональных филиалов.
4. Повышение устойчивости и внедрение экспертной поддержки
После стабилизации ситуации мы сосредоточились на предотвращении будущих кризисов:
- Настроили систему мониторинга и усиленное резервное копирование, которое позволит восстановить виртуальные машины за часы, а не недели;
- Внедрили систему заявок и подключили группового чат-бота в Telegram для лёгкого создания запросов и контроля задач;
- Перевели клиента на договор экспертной поддержки (третьей линии), что гарантирует прямое взаимодействие с высококвалифицированными специалистами по вопросам безопасности и развития ИТ-инфраструктуры.
Особенности и сложности проекта
- Масштаб миграции. Необходимо было перевести 250 пользователей в новый домен, сохранив их рабочие данные, при этом часть компьютеров требовала расшифровки дисковой системы.
- Работа с «железом». Мы устанавливали оборудование в кластерные и резервные стойки параллельно с настройкой софта. Включая настройку виртуализации с GPU-ускорением для задач, требующих высокой производительности.
- Жесткие сроки. Работы велись одновременно по всем направлениям (сеть, серверы, безопасность), что требовало ювелирной координации действий команды.
Результаты: работоспособность восстановлена, безопасность обеспечена
Благодаря выделению мощной команды экспертов, нам удалось сократить время критического простоя с нескольких месяцев до нескольких дней.
Ключевые достижения:
- Полная работоспособность всех офисов восстановлена менее чем за неделю;
- Новая инфраструктура построена на принципах отказоустойчивости, сегментации и защиты;
- Система резервного копирования позволяет восстанавливать сервисы в разы быстрее, чем до атаки;
- Организована постоянная экспертная поддержка — клиент получает квалифицированную помощь в любой момент;
- Повышена надежность ИТ-системы — внутренний ИТ-отдел компании был усилен нашей экспертизой, что позволило перевести ИТ-системы на более безопасную, управляемую и масштабируемую модель работы.
ИТ-интегратор СТЕК специализируется на комплексном аварийном восстановлении данных (Disaster Recovery) и ремедиации гибридных инфраструктур после хакерской атаки. Мы берем на себя полный цикл — от экстренного реагирования на инциденты и ликвидации последствий комплексного киберинцидента до проектирования, внедрения и долгосрочного сопровождения отказоустойчивых сред.
Если ваша компания столкнулась с серьезным IT-инцидентом или вы хотите заранее укрепить свою инфраструктуру, чтобы подобный кейс не произошел с вами — мы готовы помочь.
