Проблемы в ИТ-инфраструктуре почти никогда не возникают за один день. Чаще всего они накапливаются постепенно: бизнес растёт, увеличивается нагрузка на сервисы, появляются новые задачи, а оборудование и программные решения начинают работать на пределе своих возможностей.
В этом кейсе расскажем о модернизации клиент-серверной инфраструктуры, которая не обновлялась более 10 лет. Покажем, какие проблемы накопились за это время, чем они угрожали бизнесу, и какие ИТ-решения мы внедрили.
Исходная ситуация
У клиента была развернута IT-инфраструктура, обеспечивающая работу головного офиса и нескольких филиалов, расположенных в разных часовых поясах с разницей до 7 часов. Мы сопровождали эту ИТ-систему на протяжении длительного времени и глубоко понимали её архитектуру, сильные стороны и ограничения. Годами ранее она полностью соответствовала бизнес-задачам и выдерживала операционную нагрузку.
Однако за более чем десятилетний период накопился критический объём изменений.
Ещё два года назад в процессе обслуживания наши менеджеры обращали внимание на существующие ограничения ИТ-инфраструктуры и обозначили предварительные бюджетные рамки для их устранения.
В рамках подготовки рекомендаций были обозначены следующие ключевые проблемы:
| Проблема | Риски для бизнеса |
|---|---|
| Высокий уровень физического износа жестких дисков и устаревшее оборудование | Повышенный риск отказа оборудования, незапланированных простоев бизнес-сервисов и потери данных вследствие выхода из строя критических компонентов. |
| Низкая производительность подсистемы хранения данных из-за использования HDD вместо SSD | Снижение скорости работы бизнес-приложений, увеличение времени отклика сервисов, ухудшение пользовательского опыта и риск деградации производительности при росте нагрузки. |
| Дефицит оперативной памяти (загрузка ОЗУ гипервизора достигала 88%) | Риск нестабильной работы виртуальных машин, замедления критических сервисов, сбоев при пиковых нагрузках и невозможности масштабирования инфраструктуры. |
| Использование устаревших процессоров с производительностью на 40–60% ниже современных аналогов | Ограничение вычислительных ресурсов, снижение эффективности работы приложений, риск недостаточной производительности в периоды высокой нагрузки и сдерживание развития новых цифровых сервисов. |
| Неэффективная система резервного копирования | Высокий риск длительного простоя после сбоя или киберинцидента, потеря критичных данных и нарушение непрерывности бизнес-процессов. |
| Единые точки отказа на критических сетевых узлах | Риск полной недоступности отдельных сервисов или всей инфраструктуры при отказе одного элемента, что может привести к остановке операционной деятельности. |
| Ограниченная пропускная способность сетевой инфраструктуры (не более 1 Gbps) | Возникновение сетевых узких мест, замедление обмена данными, ухудшение доступности сервисов и ограничение дальнейшего роста бизнеса. |
| Невозможность установки актуальных обновлений и патчей безопасности | Повышенный риск кибератак, эксплуатации известных уязвимостей, нарушения требований информационной безопасности и потенциальных финансовых и репутационных потерь. |
Задача: реконфигурация клиент-серверной ИТ-инфраструктуры
Подготовка сметы и поставка серверного оборудования
Один из вызовов проекта — часть критически важных комплектующих официально не поставляется в Россию и фактически недоступна на рынке. Но благодаря собственной партнёрской сети и выстроенным международным каналам мы смогли обеспечить поставку именно тех компонентов, которые требовались архитектурой проекта — без компромиссов и замены на более слабые решения.
Заметим, что в момент согласования работ цены на оборудование росли буквально каждый день, и из-за долгого принятия решений проект мог выйти за рамки бюджета ещё до старта. Только благодаря настойчивости и оперативной реакции наших менеджеров, оборудование удалось закупить до резкого скачка цен.
Развертывание серверной группировки с репликацией
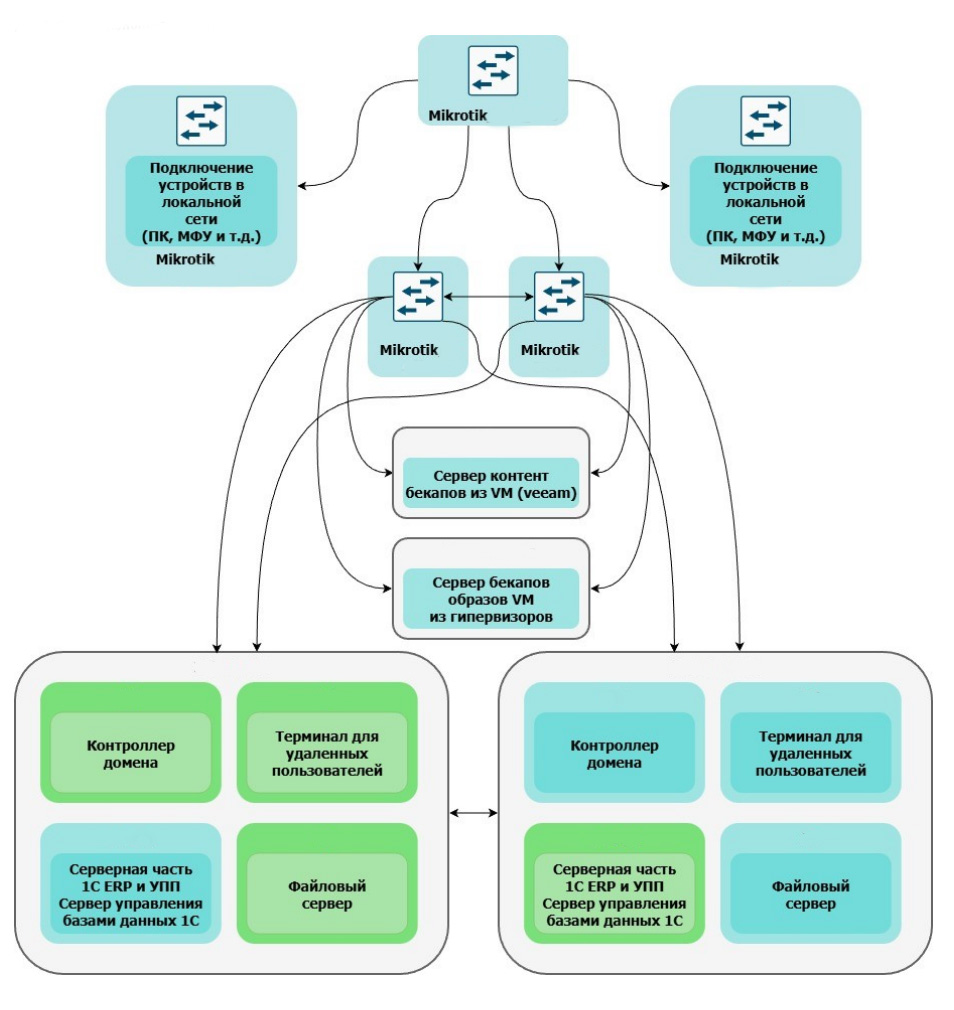
Для обеспечения высокой доступности реализована репликация виртуальных машин с отработанным сценарием аварийного переключения.
Ядро сети построено на отказоустойчивой связке управляемых коммутаторов MikroTik.
С учётом высокой нагрузки от репликации (включая бизнес-критичные системы, такие как 1С) была проведена модернизация сетевой инфраструктуры: внедрена сеть 10 GbE, устранившая узкие места и обеспечившая необходимую пропускную способность для синхронизации данных.
P2V-миграция файлового сервера
Миграция файлового сервера была одним из основных этапов проекта: разветвлённая структура каталогов и сложная система прав доступа создавали высокий риск ошибок. Наша команда заранее провела полную инвентаризацию файловой структуры и прав доступа. Благодаря этой подготовке миграция прошла с полным переносом NTFS-разрешений, политик доступа и сетевых ресурсов. Пользователи сохранили привычную структуру, даже не заметив перехода в новую ИТ-среду.
Система резервного копирования

В ходе модернизации инфраструктуры была проведена оценка ранее используемого оборудования для его дальнейшего применения. Часть ресурсов интегрировали в новую систему резервного копирования, что позволило эффективнее использовать существующую инфраструктуру и сократить затраты на внедрение решения.
Система резервного копирования была спроектирована с учётом требований к отказоустойчивости, скорости восстановления данных и непрерывности работы критически важных сервисов.
Новая система резервного копирования охватывает как корпоративные данные, так и полные образы виртуальных машин, что позволяет в случае сбоя практически мгновенно восстановить ИТ-инфраструктуру.
Миграция сервисов и пуско-наладка
Перенос ключевых сервисов (ядро 1С, терминальная инфраструктура и сопутствующие сервисы) выполнялся в ночное время для максимального сокращения простоя бизнес-процессов. Был разработан строгий план миграции — сначала перенос систем управления и баз данных (1С), затем терминальных серверов, в конце — вспомогательных служб.
Особую сложность создавал географически распределённый бизнес клиента: пока в одном часовом поясе завершались ночные работы, в другом офисе уже начинался рабочий день. Поэтому команда не только выполнила миграцию, но и организовала ночное дежурство с усиленным мониторингом запуска сервисов, чтобы оперативно отреагировать на любые сбои. Благодаря чётко скоординированной работе все системы были запущены в штатном режиме, а переход прошёл без влияния на работу компании.
Ключевые результаты
Инфраструктура стала надежным управляемым ИТ-активом.
До проекта:
- При возникновении серьёзного инцидента восстановление инфраструктуры могло потребовать значительного времени и привести к длительной недоступности сервисов.
- Ограниченные ресурсы инфраструктуры усложняли развитие сервисов и увеличивали риски простоев.
- Процедуры восстановления зависели от ручных операций и не обеспечивали необходимой скорости возврата сервисов к работе.
После внедрения:
- Доступность сервисов повысилась за счет комбинации отказоустойчивой инфраструктуры и перехода на современное серверное оборудование.
- Время восстановления (RTO) сокращено с дня до двух часов.
- Риск безвозвратной потери данных устранён: сегментация и изолированные резервные копии нивелируют сценарии вирусов-шифровальщиков.
- Произведен переход на аппаратную платформу с горизонтом планирования на 4 года, что дало значительный рост производительности критических сервисов.