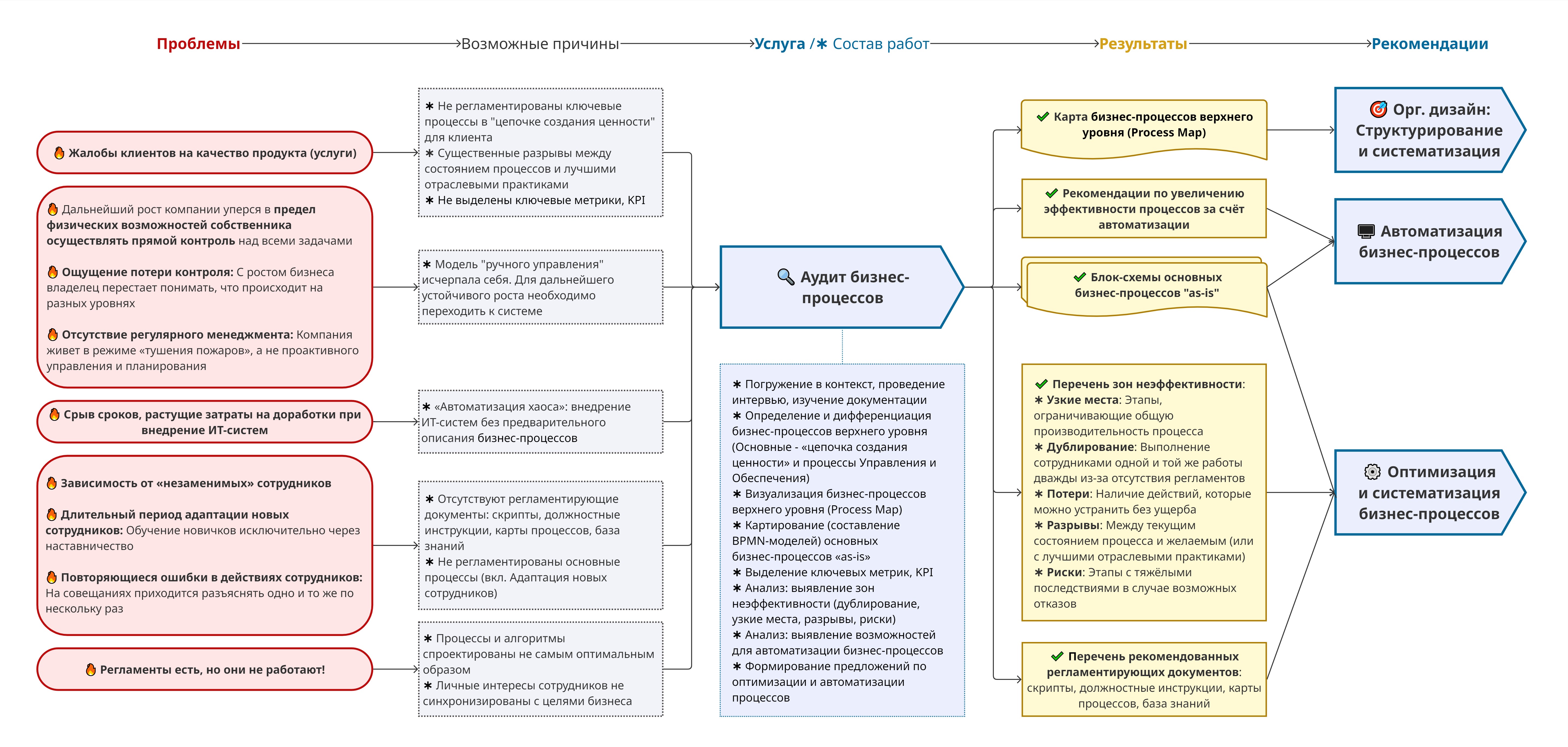
В данном кейсе раскрывается несколько частых проблем многих компаний:
- Отсутствие резервирования баз данных;
- Отсутствие централизованного сбора информации обо всех устройствах в ИТ-инфраструктуре;
- Отсутствие контроля за актуальностью мощностей оборудования в развивающейся IT-системе;
- Халатное отношение штатных сотрудников к ИТ-инфраструктуре компании.
Мы покажем на наглядном примере к чему это может привести, и расскажем, как в экстренном режиме спасали ИТ-системы клиента.
Описание аварийного инцидента
Для лучшего понимания всей картины кратко опишем структуру компании-клиента. Заказчик — крупная сеть кондитерских, чью ИТ-инфраструктуру обслуживает собственный ИТ-отдел (два системных администратора).
Ситуация сложилась так, что примерно в одно время из ИТ-отдела клиента уволились оба специалиста. При этом ими не была подготовлена необходимая база данных о состоянии ИТ-инфраструктуры и текущих задачах. Отсутствие контроля за процессом увольнения ИТ-специалистов привело к тому, что компания не просто осталась без технической поддержки, но и оказалась без какой-либо информации о собственных IT-системах. В таком безнадзорном режиме ИТ-сервисы проработали около месяца, после чего стали появляться ошибки, которые застопорили работу «1С».
Собственными силами (посредством обращения к стороннему ИТ-специалисту) клиент выяснил, что доступа к главному маршрутизатору и другим системам нет, потому что все пароли изменены. Однако никто из бывших ИТ-инженеров клиента ничего об этом не знал.

Бизнес-процессы более 80 филиалов компании оказались под угрозой — системы «1С» перестали работать, отсутствовали доступы к ИТ-инфраструктуре и какой-либо Disaster Recovery план, при этом была большая вероятность возникновения других критических ошибок.
С этого момента компания начала бить тревогу.
На протяжении недели предприятие искало организацию, которая может срочно помочь с восстановлением доступов и работоспособности ИТ-систем. В конечном итоге, благодаря рекомендации, клиент обратился к нам.
Исходные данные
В очередной раз мы столкнулись с задачей, когда в большой ИТ-инфраструктуре аварийная ситуация, а доступов для её разрешения нет. Но самое опасное для компании было то, что у них отсутствовали какие-либо резервные копии баз данных и конфигурации роутера. Это значит, что при сбое ИТ-системы может быть потеряна вся информация без возможности восстановления. И, следовательно, бизнес встанет на неопределенное количество времени.
С чем мы имеем дело:
- Отсутствие резервирования данных;
- Отсутствие технической информации о более 80 филиалах компании;
- Отсутствие доступов в ИТ-инфраструктуру и к конфигурации основного маршрутизатора;
- Необходимость срочного решения данного чрезвычайного происшествия.
Аварийное восстановление ИТ-инфраструктуры
В самом начале работы мы зарезервировали все данные, к которым был доступ, и создали точки восстановления, чтобы при неожиданном сбое систем информация не была бы утрачена. Это было минимальной экстренной защитой ИТ-инфраструктуры.
Для реализации проекта предстояло с нуля написать большую конфигурацию маршрутизатора (500 строк кода), загрузить её в новый роутер и заменить старое устройство.
Сбор информации
Чтобы написать новую конфигурацию роутера требовались сведения обо всех устройствах в филиалах — их IP-адреса, доступы и настройки. Но у клиента отсутствовала единая база с этими данными, поэтому первым этапом стал сбор необходимой информации.
Наши инженеры приступили к работе.
Устранение внезапных ошибок на серверах клиента
В процессе работы всплыла еще более опасная проблема — на сервере стали давать сбои виртуальные машины. Неправильные настройки виртуализации привели к тому, что начало заканчиваться свободно место на жестких дисках. Если говорить более детально — место «съедалось» snapshot-ами самих же виртуальных машин. Это «стихийное бедствие» грозило обвалом всей системы! Здесь могло порадовать только наличие у клиента некоторых административных прав доступа к серверам. Однако некоторые сервера пришлось перезагружать и настраивать заново.
Наши инженеры незамедлительно приступили к резервированию данных, созданию точек восстановления и реконфигурации виртуальных машин. Благодаря своевременному вмешательству удалось устранить эту брешь в ИТ-инфраструктуре и спасти серверы.
Установка нового маршрутизатора и подключение всех филиалов
После настойки резервирования и отладки виртуальных машин, наш инженер подготовил конфигурацию маршрутизатора и создал её резервные копии. Затем была проведена работа «в поле» — выезд в главный офис компании и физическая замена старого маршрутизатора новым.
После запуска нового роутера, благодаря грамотным настройкам, к нему подключилось около 60 точек (из 80-ти). Остальные устройства были добавлены в ручном режиме — инженер отслеживал входящие запросы на роутер и постепенно, в реальном времени, добавлял оставшиеся точки, удалённо контролируя их работоспособность в магазинах.
В конечном итоге, благодаря непрерывной работе были подключены все филиалы, и работа систем восстановлена.
Рекомендации клиенту по обновлению оборудования
Как только все срочные задачи по восстановлению инфраструктуры были закрыты, мы подготовили для клиента ряд советов по улучшению быстродействия и надежности IT-систем. Одним из главных пунктов было обновление оборудования. Гигантская инфраструктура компании-клиента держалась на устаревших устройствах, которые едва ли могли предоставить необходимые мощности для современного бизнеса.
К примеру, одной из наших рекомендаций была замена основного коммутатора, подключенного между серверами. Его максимальная скорость передачи данных составляет 100 Мбит/с, в то время как подобного масштаба инфраструктура требует до 10 Гбит/с! Также были составлены рекомендации по замене серверов и повышению отказоустойчивости систем.
Результаты
- 1В экстренном режиме была спасена ИТ-инфраструктура и бизнес-процессы клиента;
- 2Настроено резервирование всех данных и созданы необходимые точки восстановления систем;
- 3Отлажена работа виртуальных серверов;
- 4Собрана и сохранена в одной базе информация обо всех точках компании, подготовлен минимальный DRP (disaster recovery plan — план аварийного восстановления);
- 5Клиенту даны рекомендации по обновлению технической составляющей — перечень необходимого оборудования, соответствующего запросам современной мощной ИТ-инфраструктуры.

Данный проект можно назвать показательным — в очередной раз мы помогаем в ситуации, когда ИТ-инфраструктура крупной организации практически развалилась из-за халатного отношения и низкой квалификации штатных сотрудников клиента.
Информационной безопасности уделялось недостаточное внимание, и бизнес был подвержен риску.